TwitterのOAuthでrequest tokenを取得しようとして401 Unauthorizedがでるときの原因と対処法3つ
たとえばRubyのOAuth Gemだと
OAuthConsumer#get_request_tokenすると
OAuth::Unauthorized - 401 Unauthorized:
みたいなそっけないエラーがでてどうしたらいいかサッパリわからない時がある。
一応KeyとSecretを確認したけど合ってるし……みたいなとき
俺が調べたところ原因は3つあって
- コンピュータの時刻が狂っている
- アプリがTwitterからSuspendされてる
- アプリの設定画面のCallbackURLに何も入力されていない
最後のが特に気づきにくくてすごく厄介だ。
WebアプリなどでCallbackを用いる場合
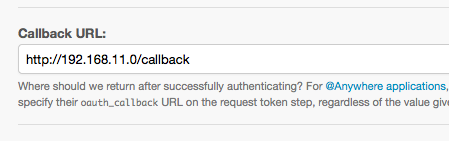
ここんところに適当でいいので何かURLを入力しておかないといけない。
本当に適当でいいみたいなので何かを入れておこう!
Twitterが悪いのかOAuthが悪いのか知らないけどひでえ仕様
カタログスペックではわからないMacBook Airの欠点
今までMacBook Pro 13inch Mid 2010を使っていたんだけど新型のAir 13inchに乗りかえた!
で、薄さと安さのために意外と犠牲にされているところがあるように感じられたのでかいとく
操作性
- キーボード 浅い。ベコベコしている
- トラックパッド アルミになったせいで滑りが悪い気がする
液晶
ProではグレアだったがAirでは低反射のグレアになっている。パッと見ノングレアに見える。
薄くできる液晶を使っているためか発色は悪い。モニタはちゃんとSpyderでキャリブレーションする色に細かい芸大の友人に聞いたらやっぱり悪いそうだ。
スピーカの音
Proに比べるとだいぶ悪い。音楽を再生すると誰でもわかるレベル。まあスピーカは基本的に重いほうが音がいいので、軽いと音が悪くなるのは当たり前だよね
バッテリー
Proの半分しかもたない。というかProのバッテリー量が異常だった。
LANポート
無いと地味に困るケース多め。ホテルとか。USB変換ケーブルかって持ち歩くしかないか…
パフォーマンス
基本的にAirのほうがよかった
- ストレージ Airにして良かった! SSDは最高だった! ノートを揺らすとHDDが「カコン」と鳴る精神衛生によろしくない現象から解放された!
- CPU いくらSandyBridgeとはいえ0.7Ghzのクロックダウンになるので厳しいかと思ったが意外と大丈夫だった。ニコ動やYoutubeでの動画再生では今までとあまり変わらない感じ。
- GPU Macでゲームしないのでわからない
| モデル名 | MBP 13inch(今まで) | MBA 13inch(買ったの) |
|---|---|---|
| OS | Snow Leopard | Lion |
| CPU | Core2Duo 2.4GHz | Core i5 1.7GHz |
| メモリ | 4GB | 4GB |
| ストレージ | 256GB | 128GB |
| 光学ドライブ | DVDマルチ | なし |
| ディスプレイ | 13.3(1280×800) | 13.3(1440×900) |
セプキャンのチュータ応募に落ちてしまい大変残念なので応募した文章晒す
すごく残念です
プログラミングコースのチュータに応募します。
私にとってセキュリティ&プログラミングキャンプは人生の大きなターニングポイントでした。それまでプログラミングに関して具体的な目標もなく、友だちもいなかった私ですが、このキャンプを通してその両方を見つけることができました。今年のキャンプではチュータとなり自分と同じように受講生がすばらしい体験をすることの手助けになれたらと考えています。
言語について
使える言語
言語好きなのと、色々なプラットフォーム・状況でプログラムを書いてきたので、そこそこの数の言語が使えると思います。実際に動く実用的なプログラムを書いたことのある言語は下記のとおりです。
C, C++(CUDA, OpenCL含む), Ruby, JavaScript, JScript, Java, C#, AS3, Perl, Python, Scheme, CommonLisp, アセンブラ(PIC, H8), VerilogHDL
パーサ
yacc, lexで関数電卓を書いたことくらいがあります。
最近は電子書籍プログラム用のマークアップフォーマットとしてraccを使って簡単なパーサを作りました。
https://gist.github.com/1102245
作った言語
言語というと大げさですが、JavaScriptでBASICもどきな言語を作りました。
どちらかというとアセンブラに近い言語になってしまっていますが、「変に構えず難しいことをせずに最小限の言語をつくるとこんなかんじ」というものを作り、その過程を書くことで、自分の言語やDSL作りに挑戦する人が増えると嬉しいと思って書きました。
http://wise9.jp/archives/1608
Ruby
MLはひと通り購読していています。
パッチを書いたことはありませんが、気に入らない仕様について小さなFeature提案をしたことはあります。
http://d.hatena.ne.jp/yayugu/20110526/1306371841
それから、より高速なプログラムを書いてRubyのベンチマークスコアの高速化に貢献しました。
http://d.hatena.ne.jp/yayugu/20110712/1310461636
その他
blog: http://d.hatena.ne.jp/yayugu
github: https://github.com/yayugu
未踏ユース: http://www.ipa.go.jp/jinzai/mitou/2010/2010_1/youth/gaiyou/hy-3.html
キャンプがなければ自分はプログラミングがこんなに楽しいものだとは知りませんでしたし、今はたくさんいるプログラマーの友人・知人もいなくて孤独なままだったと思います。だから他の人にもキャンプがそういう体験になって欲しい、あるいはそうじゃなくても何かも見つけられる体験になって欲しいです。そのために自分のできるかぎりでバックアップしていきたい。
なぜRubyをPythonよりもPHPよりも高速化できたか
最も有名なベンチマークサイト "The Computer Language Benchmarks Game" における最新のランキングで
Ruby 1.9 は Python3, PHP, JRuby を追い抜きスクリプト言語としてトップクラスの値を叩き出しました。

5/4の時点では最下位に近かったので大きく前進しています。

1つのパッチで520%の高速化を達成
この高速化は私がfastaというベンチマークのプログラムを改善したことにより実現しました。
他の人のプログラムや統計を眺めていたとき、fastaに関してPythonが異常に速いことに気づきました。
他のスクリプト言語のおよそ50倍速く、アルゴリズムが改良されていました。
この2つのコードを比較するとわかるのですが、処理が重複している箇所について事前にテーブルを作成しています。
Perlに負けた理由
最初のスクリーンショットではPerlには負けてしまっています。これはPerlでは同様のアルゴリズムの改善を行ったプログラムが6/9に投稿されて、
これと私のRubyのものの2つのプログラムが今日(7/12)に取り込まれたためです。
スコアを向上させる方法
"The Computer Language Benchmarks Game" では
という方法で言語(処理系)のスコアを求めています。
例えば現在の Ruby 1.9 のスコアは36.77ですので
Ruby 1.9 v.s C++ GNU g++

ここをみて35付近を基準に高速化する必要があります。
まずfasta, regex-dna, pidigits, reverse-complement, binary-treesは中央値よりも値が小さいのでこれ以上高速化しても意味がありません。
ベンチマーク数は10なのでスコアは中間に近い
(binary-trees + k-nucleotide) / 2 = 35.5
で求められます。従ってこの2つは少しでも高速化すればスコアの改善に直結します。
より最速より遅いspectral-norm, n-body, fannkuch-redux, mandelbrotはk-nucleotideの50よりもさらに小さな値にできない限り高速化しても意味がありません。
このようにスコアの算出方法を考慮することで効率的にランキングを上昇させることができます。
まとめ、あるいはなぜベンチマークのスコアが実際の速度とあまり関係がないのか
- "The Computer Language Benchmarks Game" はゲームです! プログラマにとって最高に楽しいゲームです!
- だから実際の言語の速度とはあまり関係がないこともよくあるんです!
NokogiriでXMLをガチParseするためのメタプログラミング
要約
RubyでHTMLからTeXへのトランスレータを書いた。
NokogiriのNokogiri::XML::SAX::Documentあたりを使うのが便利そうに感じたが、実際にやるとソースコードが崩壊した。
SAXではなくDOMを用いて階層構造を再帰で辿ったほうがいい。さらにメタプログラミングを用いると割と簡潔な記述にできる。
原因
RubyでのXML操作にはデファクトスタンダードとなりつつあるNokogiri。
HTMLから特定のタグを抽出して……のようなお手軽パースには大変快適なんですが、XMLの全部のタグにアクションを起こすような本格的にパースするとき、すごくやりづらい気がする。そもそもググッてもロクなexampleがでてこない
しょうがないので試行錯誤して、まずNokogiriのSAXを使った。
SAXはXMLを「要素の始まり」、「要素の終わり」、「テキスト」の3つにわけ、それぞれで定義した関数を呼ぶ、
# <title>Hello</title><br>World #=> \title{Hello}\par{}World class HTMLDoc < Nokogiri::XML::SAX::Document def start_element name, attrs = [] case name when 'title' @tex << '\\title{' when 'br' @tex << '\\par{}' end end def end_element name case name when 'title' @tex << '}' end end def characters str @tex << str end end
SAXはシンプルでお手軽であるが、要素が増え、扱う内容が複雑になると、「要素の開始」と「要素の終了」、「要素内のテキスト」の処理をそれぞれ別の位置で行うことによるコードの分断化が激しくなる。
たとえばこんなふうに、
# aタグの処理の流れを追ってみよう! class HTMLDoc < Nokogiri::XML::SAX::Document def initialize t @t = t ... end def start_element name, attrs = [] case name when 'set' set_option attrs when 'title' @mode.push :title when 'author' @t.body << "\n\n\\hfill " when 'br' @t.body << '\\par{}' when 'p' @t.body << "\\vspace{1zw plus .1zw minus .4zw}\n\n" when 'hr' @t.body << " \\vspace{1zw plus .1zw minus .4zw}\n\n \n\n\\noindent \\hfil \\rule{#{@t.textwidth_consider_column * 0.7}pt}{.01zw} \\hfill\n\n" when 'a' @mode.push :a_link @t.body << begin_a(attrs) ........ end def end_element name case name when 'title' @mode.pop when 'author' @t.body << "\n\n" when 'rb' @t.body << '}' when 'rt' @t.body << '}' when 'rp' @mode.pop when 'a' @mode.pop @t.body << end_a .... end def characters str case @mode.last when :ignore return when :title .... else .... end end def begin_a attrs url = '' attrs.each_slice(2) do |key, value| case key when 'href' @a_url = value end end ... end def end_a "\ \\special{color pop}\ \\special{pdf:eann}" end ....... end
SAXからDOMへ
DOMを再帰的にたどるパースを行うようにした。タグと処理のディスパッチがめんどうそうなので__send__でタグ名のメソッドを呼び出すことにする。
class TransformHTMLToTex def initialize t=nil @t = t @zenkaku_kagikakko = false @force_kansuji = false end def parse n if n.kind_of?(Nokogiri::XML::NodeSet) n.map do |node| _parse node end.join('') else _parse n end end def _parse node if node.kind_of?(Nokogiri::XML::Text) text(node.content) elsif node.kind_of?(Nokogiri::XML::Node) begin @node = node @recur = proc{self.parse node.children} self.__send__('tag_' + node.name.downcase) rescue NoMethodError self.parse node.children end else raise "Cannnot parse. Unknown Node: #{node.class.inspect}" end end def recur @recur.call end def text str to_kansuji!(str) if @force_kansuji tex_escape!(str) str.gsub! /「/, '{\makebox[1zw][r]{「}}' if @zenkaku_kagikakko if @hyperlink a_text str else str end end def title h = @t.fontsize / 2.0 @node.content.each_char.map do |char| "\\raisebox{0pt}[#{h}pt][#{h}pt]{\\Huge\\mcfamily\\bfseries #{char}}\n" end.join('') end def author() "\n\n\\hfill #{yield}\n\n"; end def rb() "\\kana{#{yield}}"; end def rt() "{#{yield}}"; end def rp() ""; end def br() '\\par{}'; end def hr "\ \\vspace{1zw plus .1zw minus .4zw}\n\n \n\n\\noindent \\hfil \\rule{#{@t.textwidth_consider_column * 0.7}pt}{.01zw} \\hfill\n\n" end def p() "\\vspace{1zw plus .1zw minus .4zw}\n\n#{yield}"; end .......
TransformHTMLToTex.new.parse(Nokogiri::HTML(url))
のようにして呼び出せる。SAXの場合と違い、それぞれのタグへの処理が一箇所にまとまっている。
またタグを処理するメソッドに、子タグの処理のやり方をBlockでわたしているため、子タグを処理する/しないをyieldを呼ぶかで制御できる。
名前の衝突の解決、内部DSLチックに
このままだとクラス内の他のメソッドと名前が衝突してしまっている。クラスないで
p debug
とかくとpタグ処理メソッドが呼び出されてしまうし、
そこで直接関数を定義するのではなくdefine_methodでtag_title, tag_aのようなメソッド名を定義することにする。
define_methodではyieldが使えなくなることに悩んだが、インスタンス変数でブロックを渡すことにした。
class TransformHTMLToTex def self.tag name, &block define_method('tag_' + name.to_s, block) end def initialize t=nil @t = t @zenkaku_kagikakko = false @force_kansuji = false end def parse n if n.kind_of?(Nokogiri::XML::NodeSet) n.map do |node| _parse node end.join('') else _parse n end end def _parse node if node.kind_of?(Nokogiri::XML::Text) text(node.content) elsif node.kind_of?(Nokogiri::XML::Node) begin @node = node @recur = proc{self.parse node.children} self.__send__('tag_' + node.name.downcase) rescue NoMethodError self.parse node.children end else raise "Cannnot parse. Unknown Node: #{node.class.inspect}" end end def recur @recur.call end def text str to_kansuji!(str) if @force_kansuji tex_escape!(str) str.gsub! /「/, '{\makebox[1zw][r]{「}}' if @zenkaku_kagikakko if @hyperlink a_text str else str end end tag :title do h = @t.fontsize / 2.0 @node.content.each_char.map do |char| "\\raisebox{0pt}[#{h}pt][#{h}pt]{\\Huge\\mcfamily\\bfseries #{char}}\n" end.join('') end tag(:author) {"\n\n\\hfill #{recur}\n\n"} tag(:rb) {"\\kana{#{recur}}"} tag(:rt) {"{#{recur}}"} tag(:rp) {""} tag(:br) {'\\par{}'} tag :hr do "\ \\vspace{1zw plus .1zw minus .4zw}\n\n \n\n\\noindent \\hfil \\rule{#{@t.textwidth_consider_column * 0.7}pt}{.01zw} \\hfill\n\n" end tag(:p) {"\\vspace{1zw plus .1zw minus .4zw}\n\n#{recur}"} ........
pTeXで縦書きモード時にハイパーリンクを埋め込む方法のメモ
TeXでハイパーリンクを埋め込んだり、PDF内での参照をクリックでジャンプできるようにしたりするためにはhyperrefが標準的に使われております。hyperref便利なんですがpTeXの縦書きモードには対応していなかったようで、リンクの部分のテキストが和文のとき英文と同じように右に90°回転してしまいます。
2日がかりでやっと埋め込める様になったのでメモしておく
プリアンブルでの正しいhyperrefの埋め込み方
例えば,下記のようにします. \usepackage[dvipdfmx,% bookmarks=true,% bookmarksnumbered=true,% colorlinks=true,% pdftitle={LaTeX研修課程},% pdfauthor={ななしのごんべぇ},% pdfsubject={hyperref入門・演習},% pdfkeywords={TeX; dvipdfmx; hyperref; color;}]{hyperref} または, \hypersetup{オプション} を使用して \usepackage[dvipdfmx]{hyperref} \hypersetup{% bookmarks=true,% bookmarksnumbered=true,% colorlinks=true,% pdftitle={LaTeX研修課程},% pdfauthor={ななしのごんべぇ},% pdfsubject={hyperref入門・演習},% pdfkeywords={TeX; dvipdfmx; hyperref; color;}}
と書いてありますがこれでは動きません。
まず下のような\hypersetupは使わないようにして上のやり方で描くようにしましょう。\hypersetupを使うと謎の警告やエラーがでて悩まされました。
次に
\usepackage[dvipdfmx,...
ではなく
\usepackage[dvipdfm,...
の方がいいと思います。というか私の環境だとdvipdfmx指定はエラーがでました。
hyperrefでリンクを貼る
pTeXでも横書きなら
\href{http://d.hatena.ne.jp}{yayuguのにっき}
のようにしてリンクが貼れます。簡単です。
しかし縦書きだと「のにっき」まで文字が回転してしまう。
拙作のparseDVIを使って解析してみたらこんな感じになっていた。
dir yoko xxx pdf:bann << /Type /Annot /Subtype /Link /Border [0 0 0] /C [0 1 1] /A << /S /URI /URI (http://d.hatena.ne.jp/yayugu) >> >> xxx color push cmyk 0 1 0 0 fnt_def brsgnmlminr-h 10.58441162109375 fnt brsgnmlminr-h 10.58441162109375 set yayuguのにっき xxx color pop xxx pdf:eann
あらら。縦書きしたいのにばっちりdir=yoko指定されちゃってますね。あらら
boxでなんとかならないかな
hboxとかを適当にかませばなんとかならないかなーと
\href{http://d.hatena.ne.jp}{yayugu\hbox{のにっき}}
みたいにしたらPDF出力に「yayugu\hbox{のにっき}」がそのままでちゃいましたorz
\hrefの引数のなかだとバックスラッシュがエスケープされちゃうみたいです。
\specialを使ってdvipdfmx向けの命令を直接書く
そういえばさっきparseDVIでdvipdfmx向けにどういう命令を送ったかみたよね。あれを真似すればいいんじゃね? と思いやってみました。
\special{pdf:bann << /Subtype /Link /Border [0 0 0] /C [0 1 1] /A << /S /URI /URI (http://d.hatena.ne.jp) >> >>}%
yayuguのにっき%
\special{pdf:eann}やった!うまくいった!
エスケープ……エスケープ…
TeXで特別な意味を持つ記号を含むURLだと上手くうごきません。
たとえば、
\special{pdf:bann << /Subtype /Link /Border [0 0 0] /C [0 1 1] /A << /S /URI /URI (http://twitter.com/_ko1) >> >>}% @\_ko1さんいわく% \special{pdf:eann}
こんなのとか。
%とかなら\%にするだけでうまくいくんですが、_(アンダースコア、アンダーバー)はまったくうまくいかない。
parseDVIしてみたところ\_は特別な命令に置換されてしまうようで、文字コードとしての_にはならない。代わりに\charとかを使ってみようとおもったんですが、\special内だとなぜか動かない。
TeXしねばいいのに
\catcodeで局所的に_とかを普通の文字列としてあつかう
_とかがTeX的に特別な記号だからいけないわけで、ふつうの文字として扱ってしまえばいいんです。
\begingroup \catcode`\_=11 \catcode`\%=11 \catcode`\#=11 \catcode`\$=11 \catcode`\&=11 \special{pdf:bann << /Subtype /Link /Border [0 0 0] /C [0 1 1] /A << /S /URI /URI (http://twitter.com/_ko1) >> >>}\endgroup @\_ko1さんいわく \special{pdf:eann}
こういうふうに書くと\begingroup〜\endgroupの内側で_, %, #, $, &が普通の文字として扱われるのでエスケープは不要に!やった!
ただし、%をコメントとして使うこともできないので%を使った改行テクニックもつかえなくなり、可読性は大幅の落ちます。
\begingroup〜\endgroupと\special{pdf:bann...〜\special{pdf:eann}が入れ子になっていなくてすごくきもちわるい
色を付けて完成!
リンクなら色つけたいですよね。これも\special命令使います。
\begingroup \catcode`\_=11 \catcode`\%=11 \catcode`\#=11 \catcode`\$=11 \catcode`\&=11 \special{pdf:bann << /Subtype /Link /Border [0 0 0] /C [0 1 1] /A << /S /URI /URI (http://twitter.com/_ko1) >> >>}\endgroup \special{color push cmyk 0.75 0.75 0 0.44} @\_ko1さんいわく \special{color pop} \special{pdf:eann}
まとめ
- hyperrefは便利
- hyperrefはpTeXの縦書きには対応していない。あきらめよう
Rubyにおけるrand(乱数)の挙動について
Rubyのrandの挙動はややこしく、最近さらにややこしくなったのでメモ。
ふるまい(before 1.9.2)
1.9.2までは、
Random#randは引数にInteger, Float, Rangeを扱うことができるのに対し、
Kernel#rand, Random.randではIntegerしか扱うことができない
rand 10 #=> 7 rand 7.5 #=> 4 rand 10..20 #=> TypeError: can't convert Range into Integer Random.rand 10 #=> 8 Random.rand 7.5 #=> 3 Random.rand 10..20 #=> TypeError: can't convert Range into Integer Random.new.rand 10 #=> 8 Random.new.rand 7.5 #=> 6.258043599450456 Random.new.rand 10..20 #=> 20
仕様変更の提案
この挙動が不満だったのでruby-listで聞いてみたところ、
「redmineに投げてみたら」
と言われたので投げたら通ってしまった。
Random#randとKernel#randでRangeを扱えるように(http://redmine.ruby-lang.org/issues/4605)
提案ないようは最初はKernel#randとかでもFloatとRangeを扱えるようにするものだったが、それだとFloat値が与えられた時の互換性がなくなってしまいヤバい。
しょうがないのでRangeの対応だけを追加するものを提案した。
実装
提案したらsora_hとmrknさんが即効でパッチを書いてくれてcommitされたようです。
ソースコードながめてたらKernel#randとRandom.randはCレベルでは全く同じ関数と知ってびっくり
まとめ
| Kernel#rand | Random.rand | Random#rand | |
|---|---|---|---|
| 1.9.2まで | Integer | Integer | Integer, Float, Range |
| 1.9.3から | Integer, Range | Integer, Range | Integer, Float, Range |
Random#randの存在を知らずに「RubyではFloatの乱数作れないのかよ……つかえねえ」とか思う人がでてこないといいなあ